ICASSP 2022 - Source Separation
This is a brief scan for ICASSP papers, searched with “source separation” (not all papers).
facebook ai 쪽 논문이고, timbre transfer 관련이라고 보면 될 것 같다.
처음에 학습 시킬 때 speaker identity에 따라 다른 timbre를 표현하게 학습시키고, 이후에 다른 목소리를 표현하고 싶으면 그 목소리와 비슷한 speaker identity를 찾는 모델이다.
speaker identity를 찾는 과정은 speech 데이터에서도 찾을 수 있고, 상대적으로 적은 데이터로 할 수 있다.
GAN 에서 G에 condition을 다양하게 줘서 노래에 대한 정보나 speaker에 대한 정보를 넘겨주고, 소리를 생성하게 하는 모델을 사용한다.
singing voice conversion 은 input으로 들어온 노래를 다른 사람의 목소리로 reproduce 하는 문제다. 이 논문의 결과는 https://singing-conversion.github.io/ 에서 들어볼 수 있다. 각 데이터에는 사람 1명의 목소리만 있다.
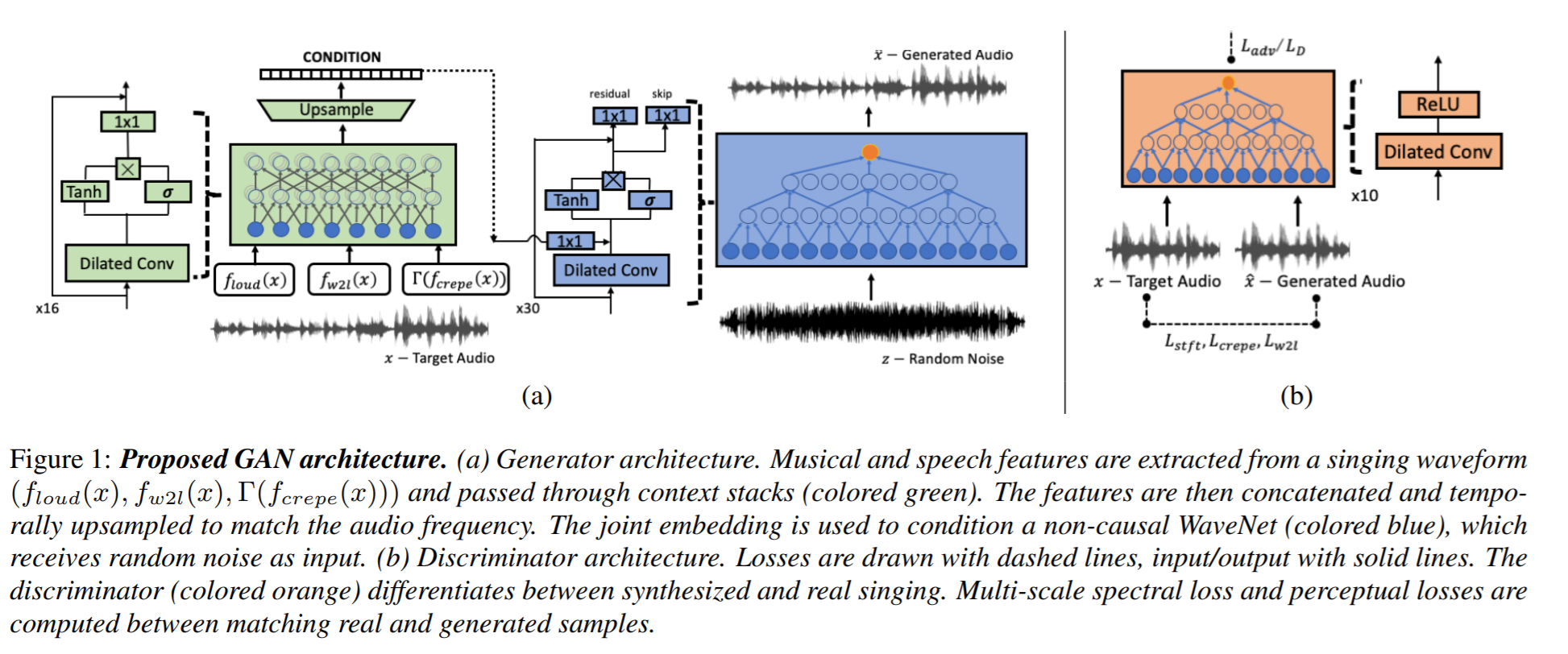
GAN을 사용하면서 G 에 parameter로 여러 가지를 넘겨주는데, speaker-invariant feature들과 speaker identity다.
speaker-invariant feature 로는 loudness, f0를 사용한다. loudness는 log-scaled power spectrum을 사용하고, f0는 CREPE를 사용해서 추출한다. f0를 그대로 사용하면 생성된 소리의 pitch가 불안정해서 single sinusoid sine-exitation $\Gamma (f_{crepe}(x))$ 를 사용한다. Speech의 경우 Wav2Letter라는 음성인식 쪽 모델을 가져와서 추가로 사용한다.
Speaker identity에 관해서는 논문에 자세히 나와있지는 않은데 이전 논문 을 참고했을 때 embedding 으로 이해하면 될 것 같다.
모델은 기본적으로 Least-squares GAN 을 따르고 있다. 학습 목표는 크게 두 가지로 나누는데, single singer objective function 세팅과 multi-singer 세팅이다.
Single singer objective function 의 아래와 같다.
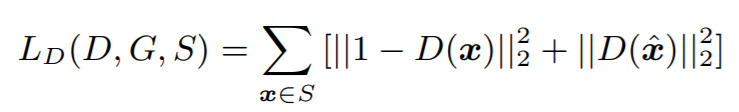
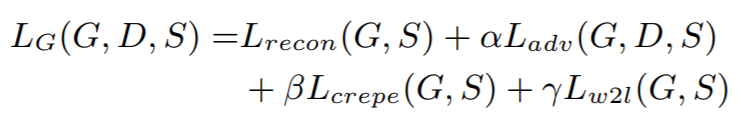
G의 objective는 여러 loss의 합으로 표현되어 있는데, adv loss 는 GAN에서 일반적으로 사용하는 objective로 볼 수 있다.

recon loss는 $\hat{x}$ 이 x를 얼마나 잘 reconstruciton 했는지 비교하는 것으로, multi-scale spectral loss를 사용한다. 아래 식에서 F 는 Frobenius norm인데, l2 norm이다. 첫 번째 term이 spectral peak 를 표현하고, 두 번째 term이 소리의 silent section에 대한 penalty라고 한다. 두 번째 term이 어떻게 그런 의미를 갖는지는 잘 모르겠다.
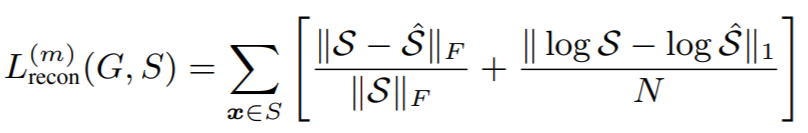
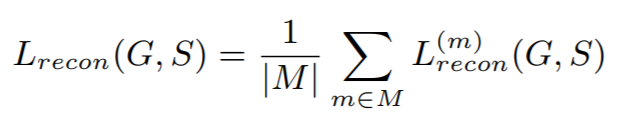
나머지 두 loss는 생성된 소리의 quality를 위한 부분이고, feature extractor로 사용한 모델들의 중간 layer의 activation을 사용한다. perceptual loss의 아이디어를 가져온 것 같다.
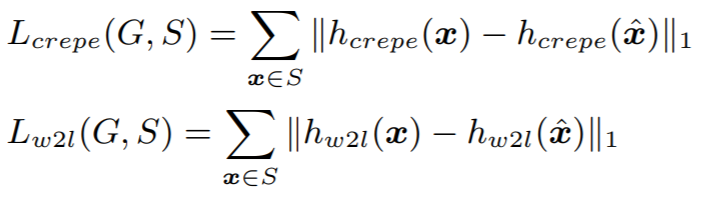
Multi-singer 세팅에서는 G에 feature 외에 speaker identity를 추가한다. 예를 들어, speaker i의 샘플을 speaker i의 소리로 recon 했을 때와 speaker j의 소리로 recon했을 때 아래와 같이 표기한다.
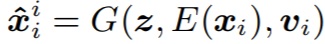
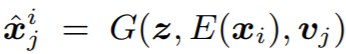
speaker 를 바꿨을 때는 recon loss를 포함시키지 않는 것을 제외하면 objective는 동일하다.
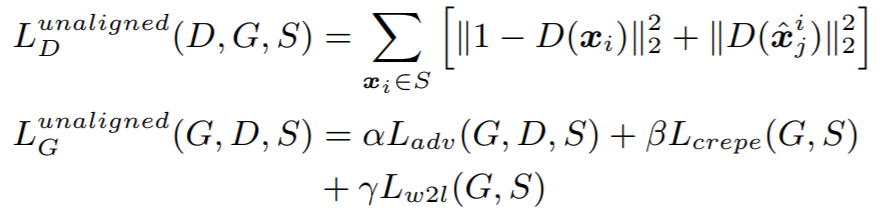
speaker identity의 convex combination을 통해 virtual speaker를 생성했다. 이 세팅을 mixup 세팅이라고 부르는데 특별한 의미가 있는지 잘 모르겠다. 다양한 speaker에 대해 결과가 잘 나오게 하는데 도움이 될 것 같다.
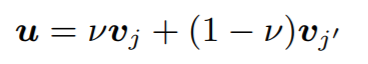
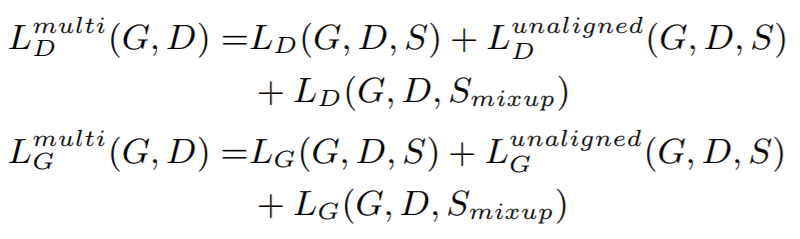
모델 구조는 non-causal WaveNet 기반이고, auto-regressive하지 않기 때문에 빠르다고 한다. 자세한 모델 구조에 대해서는 적지 않겠다.
결과는 https://singing-conversion.github.io/ 에 여러 샘플들이 있으니 바로 들어보는게 빠른 것 같다. Speech에서 학습한 speaker identity로 conversion을 하는 내용들도 포함되어 있다.
evaluation 결과는 아래와 같다.
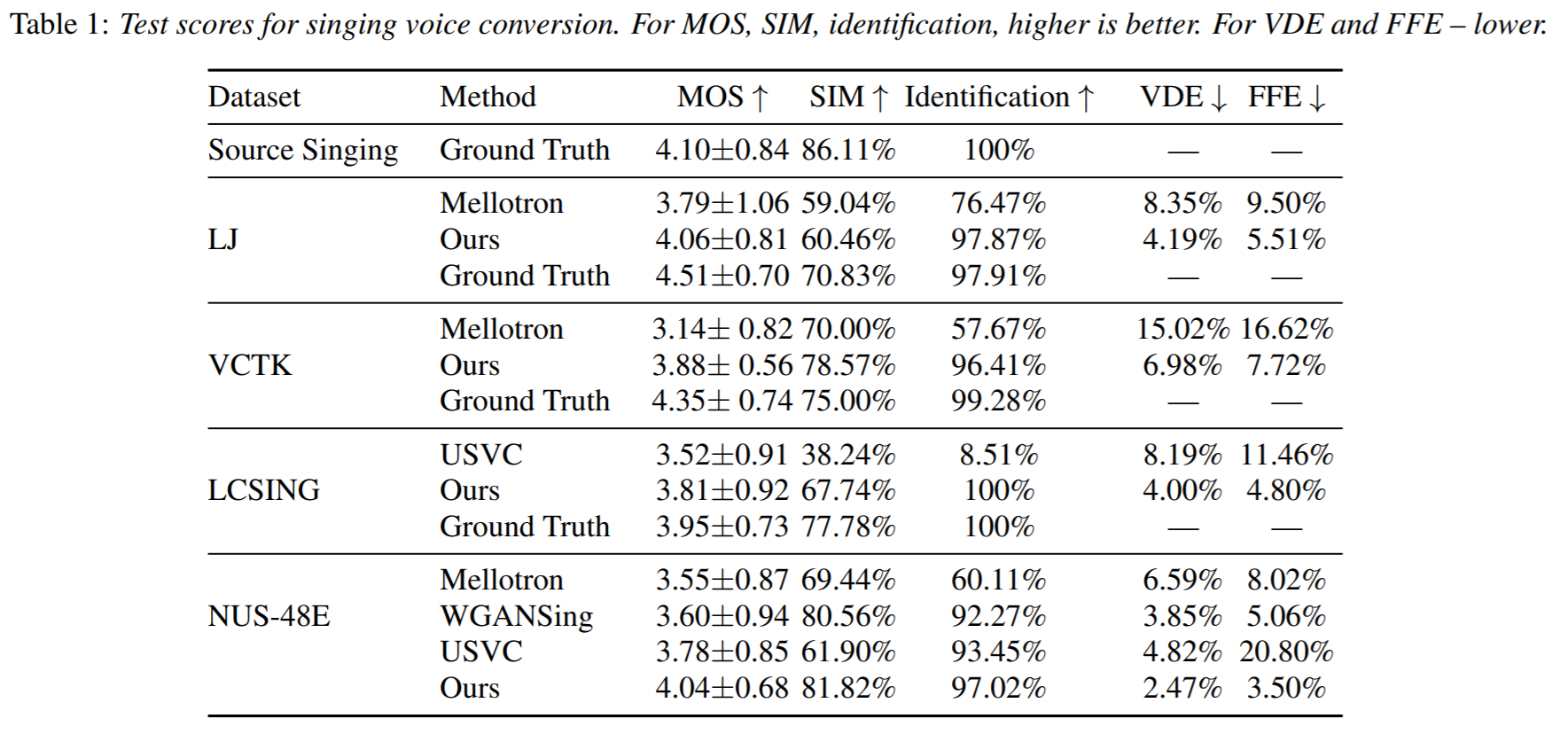
f
This is a brief scan for ICASSP papers, searched with “source separation” (not all papers).
사용 환경 : virtualbox + ubuntu server 20.04 + i3 + st-luke
title content —– ‘’’ code ‘’’