ICASSP 2022 - Source Separation
This is a brief scan for ICASSP papers, searched with “source separation” (not all papers).
facebook ai 쪽에 있는 defossez라는 아저씨 논문이다.
Demucs 라고 다른 논문들에서 baseline으로 주로 제시되는 모델 중 하나인데 publish된 적은 없는 것 같다.
데모부터 들어보면 상당히 괜찮은 결과를 보여준다. https://ai.honu.io/papers/demucs/index.html
작년에 wave u net 가지고 씨름하지 말고 이 모델을 바로 시도했으면 어땠을까 싶다.
푸는 문제는 전형적인 music source separation 문제다. mixture signal을 (1)drums, (2)bass, (3)other, (4)vocals로 구분한다.
waveform domain에서 문제를 풀기 위해서 크게 두 가지 방법을 시도한다. 기존에 존재하는 Conv-Tasnet이라는 speech source separation 모델을 음악에 적용시키는 것과 이 연구에서 제시된 demucs라는 모델이다.
Conv-Tasnet을 적용하면서 생긴 변경점을 살펴보면 아래와 같다.
L1 loss를 사용하는 이유에 대해서는 뒤에서 설명한다.
이렇게 변형한 모델의 결과를 보면 여러 단점들이 있다고 한다.(a constant broadband noise, hollow instruments attacks or even missing parts.)
저자가 생각하기에 이렇게 된 이유는 Conv-Tasnet이 기본적으로 masking 방식인데 악기(stem)들이 겹치면서 비가역적인 정보 손실이 일어나서 masking으로 그 손실을 복구할 수 없는 것이라고 분석했다.
이제 demucs 모델 구조를 설명한다. 기본적으로 demucs는 wave-u-net 구조에서 motivated 되었다는 것을 알 수 있다. wave-u-net 구조를 기준으로 설명하자면 encoder(downsampling block) 에서 conv 뿐만 아니라 GLU(gated linear unit)을 사용하고, decoder(Upsampling block) 에서도 interpolation 대신 transposed convolution을 사용한다. bottleneck 에서는 bidirectional LSTM을 사용한다. wave-u-net 보다 convolution에서 output channel을 훨씬 깊게 만들었다. 그 이외에 skip connection 이나 전체 구조는 wave-u-net 또는 u-net과 비슷하다.
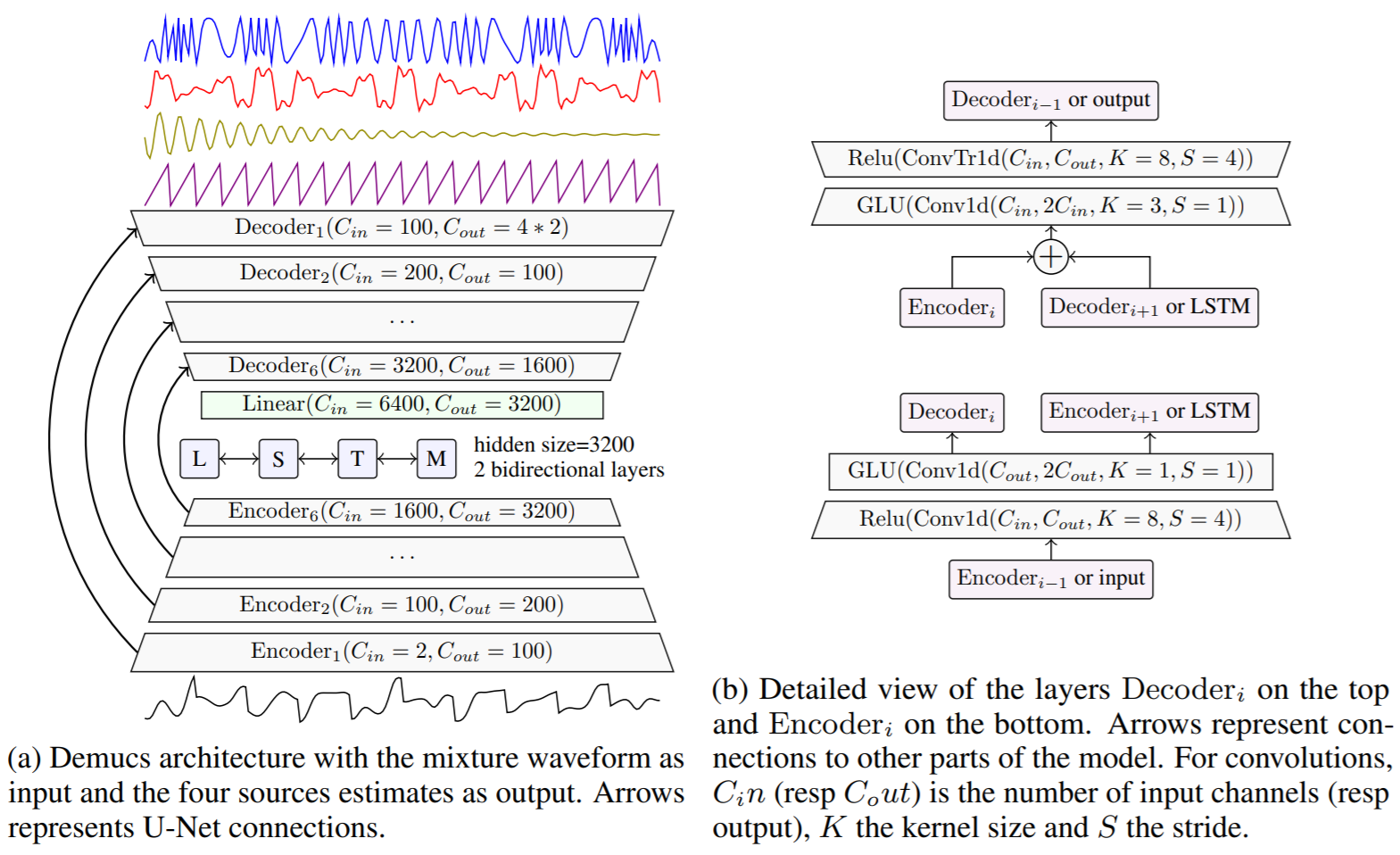
loss function은 마찬가지로 L1 reconstruction loss를 사용한다. L1 loss function을 쓰면 phase가 다른 소리에 대해 큰 loss가 나오기 때문에 문제가 될 수 있어서 sound generation task에서 spectrogram loss를 사용하는 경우가 있다. 하지만 demucs의 경우는 모델에서 원본 소리의 phase를 알 수 있고, skip connection을 통해 쉽게 phase를 복구할 수 있기 때문에 L1/L2 loss를 사용하는 데 문제가 없다고 한다.
defossez 아저씨의 이전 연구 (SING) 에서 여러 loss를 비교한 실험이 있어서 L1/l2 이외의 loss는 테스트 하지 않았다고 한다. 이전 연구에서 테스트한 loss는 L2, spectral loss 인데 multi-scale spectral loss나 SI-SDR 같은 것들에 대해서는 확인되지 않았다.
그 이외에 fixup 처럼 initialization 단계에서 rescaling을 하거나 하는 단계가 있는데 구현 세부사항인 것 같아서 생략한다.
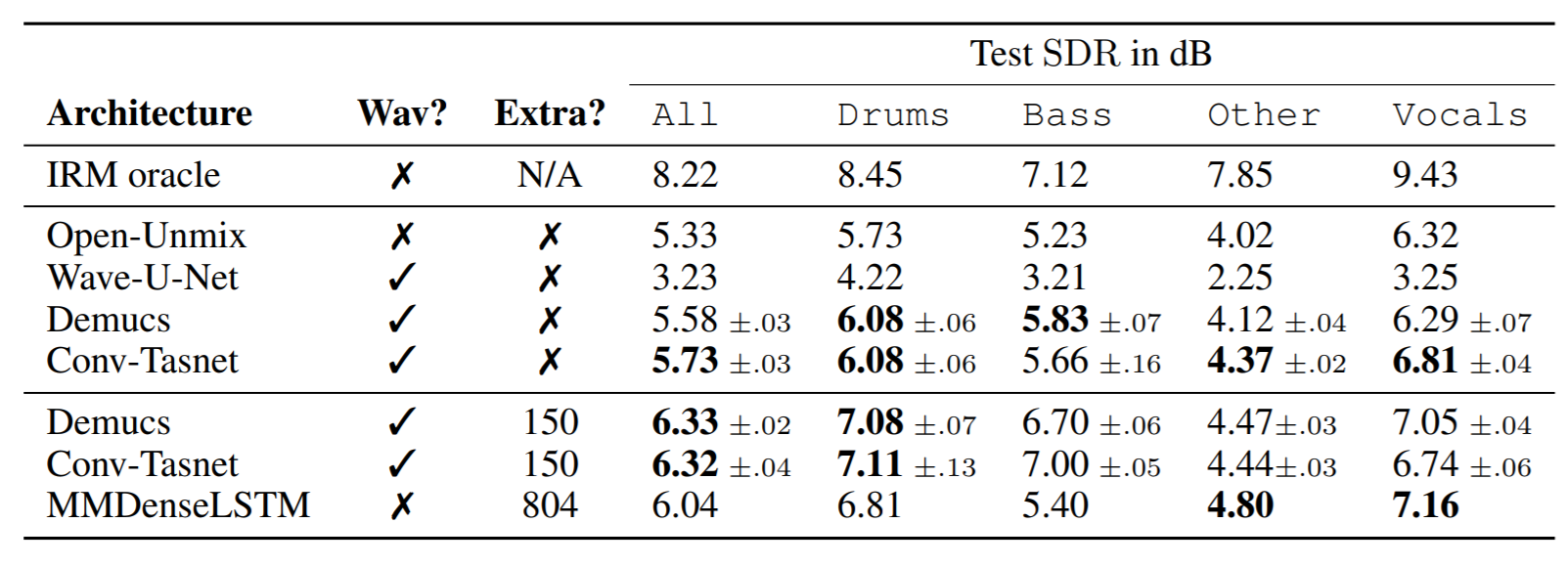
결과를 대략 보여주는 표가 있다. IRM oracle은 masking 방식의 upper bound로 생각하면 된다.
사용한 augmentation
This is a brief scan for ICASSP papers, searched with “source separation” (not all papers).
사용 환경 : virtualbox + ubuntu server 20.04 + i3 + st-luke
title content —– ‘’’ code ‘’’